

Why will 200 PFLOPS change the physics of business in 2026?
- Jan 23
- 6 min read
In a global industrial corporation, every second of delay in accessing knowledge costs thousands of euros – and every additional millisecond of latency is a direct hit to EBITDA. This is not marketing rhetoric, but a consequence of a phenomenon that data physicists refer to as Data Gravity. The petabytes of data generated by MES, PLM, and ERP systems reach a critical mass at which attempting to transfer them to the public cloud generates transfer costs and delays that negate any benefits of using artificial intelligence. In the reality of industrial production, where the assembly line does not tolerate downtime, the distance between the source of information and the computing unit ceases to be a technical parameter – it becomes a determinant of the profitability of the entire enterprise. This is exactly the point where an on‑premise sovereign cognitive infrastructure like SAVANT-AI changes the economics of AI from “nice demo” to “production‑grade profit engine”.

Traditional cloud architecture assumes that data can migrate freely to hyperscale computing centers. This assumption fails when confronted with the industrial reality of global conglomerates. When a maintenance engineer in a production plant needs immediate synthesis of a fact concerning a repair procedure for a critical machine, every millisecond of delay in translating the query through network layers translates into a real loss. Industry research indicates that highly skilled knowledge workers lose up to several percent of their working time searching unproductively through scattered information resources. On the scale of a global conglomerate, this amounts to tens of millions of euros per year – capital wasted due to an architecture that treats delay as an acceptable parameter. The answer to this systemic challenge is not another analytics platform or subscription-based cloud assistant. The answer is a fundamental paradigm shift: bringing computing power to where the data is generated.
The NVIDIA HGX B300 (Blackwell Ultra) architecture delivers 200 PFLOPS of computing power in FP8 mode – performance that allows knowledge synthesis to be generated in milliseconds instead of seconds. The system has a total of 2.3 TB of VRAM (HBM3e), enabling it to handle models with 405 billion parameters at full numerical precision without degrading quantization quality. NVLink interprocess bandwidth reaches 1.8 TB/s, eliminating bottlenecks in multi-agent orchestration processes. This specification is not an abstract technical value – it translates directly into the ability of the Enterprise Cognitive System (ECS) to perform real-time inference processes. In practice, it means that SAVANT-AI can execute thousands of concurrent, fully grounded queries from engineers, risk officers, or procurement teams, while keeping response times in the low‑millisecond range for each user.
SAVANT-AI, a sovereign cognitive infrastructure based on the Blackwell architecture, uses the Permanent Model Residency paradigm. Each intelligence unit – from the Llama‑3 405B orchestrator, through seven 70B‑class domain agents, to the deterministic fact‑verification module – resides permanently in a dedicated memory space on the accelerator. There are no “cold start” and no model swapping; every domain brain is always on, ready to answer. Zero context switching latency means that a complex query requiring data correlation from ERP, PLM, and MES systems receives a response in milliseconds, not seconds or minutes as is typical for remote inference-based solutions. For a maintenance engineer or risk officer, this is the difference between waiting 20–40 seconds for a remote chatbot and getting a fully grounded answer in under 200ms, directly on the factory or trading floor.
A critical aspect of the Blackwell architecture, often overlooked in discussions focused solely on computational performance, is the implementation of Confidential Computing technology. Inside the HGX B300 accelerators are Trusted Execution Environments (TEEs) – hardware enclaves in HBM3e memory, completely isolated from the operating system layer and processes that are not part of the certified cognitive core. Financial data, process recipes, pricing strategies, and unique technological parameters are processed in encrypted, impenetrable silicon capsules. Sovereignty, as understood by SAVANT-AI, is not a legal promise or a certificate of compliance – it is the physics of silicon, an absolute barrier guaranteed by hardware architecture. This hardware‑anchored sovereignty closes key regulatory concerns for banking, energy, and public sector organizations operating under GDPR, NIS2, and DORA.
The economic model of cloud solutions is based on variable operating costs (OpEx), which increase proportionally to the scale of system adoption within an organization. This paradox can be described as a “success tax” – the more value an organization derives from AI, the higher the bill it receives from its cloud provider. The SAVANT-AI Appliance architecture reverses this logic by converting variable operating costs into a one-time capital expenditure (CapEx) that depreciates with each knowledge orchestration session. A Total Economic Impact analysis for a global manufacturing conglomerate shows a cumulative NPV exceeding the initial investment multiple over a five-year horizon, even under conservative adoption and productivity assumptions. The dominant driver of this effect is the reduction in Mean Time to Synthesis (MTTS) – the average time it takes a knowledge worker to obtain a verified fact – by tens of percentage points across engineering, operations, and risk functions.
The key advantage of the SAVANT-AI system over traditional analytical platforms is the mechanism of deterministic fact verification (Factual Grounding) combined with Deep Citation technology. The system does not generate probable answers in a manner characteristic of probabilistic language models – it performs a process of fact orchestration, where each thesis must be justified by source evidence. Each number presented in the Cameleoo decision-making interface is accompanied by an active link leading to a specific page in the PDF documentation, a record in the ERP system, or an entry in the PLM knowledge base. The Source Traceability mechanism makes the inference process fully auditable, which is a prerequisite for compliance with ISO standards, industry regulations, and internal audit requirements. For audit and supervisory boards, this means that every AI‑assisted decision can be reconstructed, justified, and defended years after it was made.
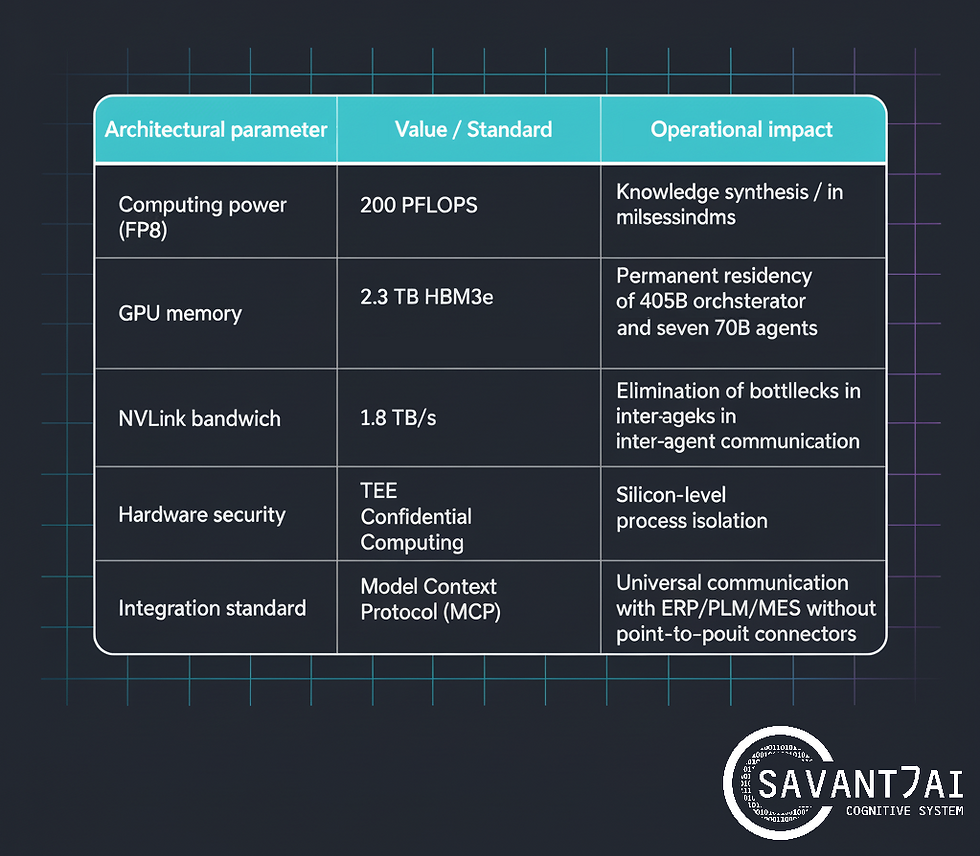
The SAVANT-AI multi-agent architecture is based on the Model Context Protocol (MCP) standard, which serves as a universal foundation for integration with corporate source systems. Instead of building costly connectors dedicated to each system-model pair, MCP introduces a client-server architecture where transactional systems share their resources through unified context servers. This turns integration from a never‑ending SI project into a standardized pattern, cutting time‑to‑value for new use cases from months to weeks. The main cognitive orchestrator (Llama‑3 405B) decomposes complex business questions into subtasks delegated to specialized domain agents responsible for extracting knowledge from specific data silos. The agents not only exchange information, but also mutually verify conclusions before aggregating them, which drastically reduces the risk of hallucinations characteristic of monolithic generative systems.
The air‑gap isolation standard, implemented in the SAVANT-AI Appliance architecture, physically cuts off the computing unit from the public Internet. This is a response to two fundamental threats: Advanced Persistent Threat (APT) attacks targeting strategic intellectual property and the risk of silent data seepage into the infrastructure of public cloud providers. Update management procedures are based on the Secure Gate mechanism using one-way data links (data diodes), which allows new model versions to be delivered securely without exposing the system to software supply chain compromise. This model reduces the financial risk associated with strategic data leaks – a risk that could cost a global industrial conglomerate hundreds of millions of euros if it materializes. From the board’s perspective, the air‑gapped SAVANT-AI Appliance behaves like a digital firebreak: it limits the blast radius of any cyber incident by design, not by policy.
Industrial organizations are currently facing an existential choice. Continuing with a strategy based on distributed cloud solutions leads to the perpetuation of AI Sprawl – technological chaos in which dozens of uncoordinated AI initiatives generate costs without building a lasting competitive advantage. The alternative is to consolidate around a sovereign cognitive infrastructure that transforms data into strategic knowledge where that data is created. SAVANT-AI, based on the NVIDIA Blackwell HGX B300 architecture, is not just another tool in the IT arsenal – it is the digital nervous system of the corporation, capable of orchestrating knowledge in real time, with sovereignty guaranteed at the level of silicon physics.
In the next 2–3 years, planning a CapEx budget for the implementation of SAVANT-AI Appliance in air‑gap mode will be treated as an investment in critical infrastructure, analogous to the purchase of backup generators or fire protection systems. The difference is that this infrastructure does not protect against loss but builds the ability to monetize the organization’s knowledge at a rate that is impossible for competitors operating in the cognitive rental model to achieve. Organizations that do not have sovereign ECS infrastructure in 2026 will pay a success tax to hyperscalers or, worse, will have no “success to tax”. For CIOs, CFOs, and Chief Risk Officers, the practical next step is simple: treat SAVANT-AI Appliance as a line item in the 2026–2027 critical infrastructure CapEx plan. Organizations that move early will lock in computing sovereignty at 200 PFLOPS while their competitors are still negotiating usage‑based AI pricing.



Comments